

Why Too Many Automations Create Hidden Failure Points
Automation has become a default response to operational pressure. When processes slow down, when teams struggle to scale or when exception volume rises, automation is often the first lever pulled.
In many enterprises, this works, initially.
Workflows begin to run. Integrations deliver data. Jobs are complete on schedule.
From a technical standpoint, the environment appears stable. Yet over time, a different pattern emerges. Outcomes become inconsistent. Exceptions quietly accumulate. Small changes trigger a disproportionate impact. The system still runs, but confidence in it erodes.
When this happens, the instinct is to look for a technical cause. Another tool. A better platform. More automation coverage.
In most cases, that instinct is misguided.
Automation rarely creates these problems. It exposes and amplifies conditions that already exist in the underlying process. When applied to ambiguous, unstable or weakly governed processes, automation scales failure faster than it reduces effort-even when the technology itself is functioning correctly.
This brief explains why that happens, how hidden failure points form and why sequencing and process maturity determine whether automation stabilizes an ERP environment or quietly destabilizes it.
The Automation Acceleration Problem
Automation today is easier to deploy than at any point in the past. Workflow orchestration, integration of automation, low-code platforms and embedded intelligence allow teams to automate decisions and handoffs rapidly. In many cases, automation can be implemented faster than the organization can fully understand the process it is automating.
Process discipline does not scale at the same speed.
Clear ownership, consistent execution, stable master data and reliable performance measurement require coordination across teams. They demand agreement on how work should flow and who is accountable when it does not. These elements mature slowly by comparison.
The result is an imbalance.
Automation accelerates execution while process maturity lags behind.
When that happens, work does not disappear; it moves. Manual effort shifts from execution to monitoring, exception handling, reconciliation and escalation. People become responsible for detecting and correcting outcomes that automation produces on a scale.
This shift changes how failure presents itself. Instead of visible breakdowns, organizations experience gradual erosion: more follow-ups, more “edge cases,” more manual cleanups around workflows that are technically completed.
None of these suggests automation is a mistake. It does suggest that automation magnifies the consequences of unresolved process issues.
Why Automation Rarely Fails Loudly
One of the most challenging aspects of over-automation is that it seldom produces obvious failure signals.
Modern automated systems are designed to keep moving. Workflows retry. Integrations deliver eventually. Jobs complete with partial inputs. From an infrastructure perspective, the system remains healthy.
From a process perspective, failure accumulates quietly.
Exceptions are the most common entry point. When process boundaries are unclear or ownership is undefined, edge cases are routed into generic queues or fallback paths. These queues grow slowly and are often invisible until they disrupt downstream work.
Retry logic compounds on the issue. Retries preserve technical delivery but can obscure correctness. Late updates, duplicated events and reordered transactions do not stop the system, but they distort operational reality.
Downstream propagation completes the pattern. Small defects introduced early are multiplied as data flows through dependent systems, reports and reconciliations. By the time inconsistencies are detected, the root cause is difficult to trace back to the automation that introduced them.
This is why organizations often describe their environment as “working, but brittle.” The technology is functioning. The process is not.
Process Conditions That Become Hidden Failure Points
The following conditions are frequently labeled as technical issues. In practice, they are process failures that automation makes impossible to ignore.
Undefined Exception Ownership
When exceptions occur, someone must own them. Not just triage, but resolution authority and backlog governance. In many environments, ownership is implicit or fragmented.
Automation increases throughput. Exception volume rises accordingly. Without clear ownership, exceptions become a permanent shadow process—worked informally until escalations force attention.
Symptoms include growing queues, unclear SLAs and escalation-driven detection. Teams often misdiagnose this as a tooling limitation, when the root issue is accountability.
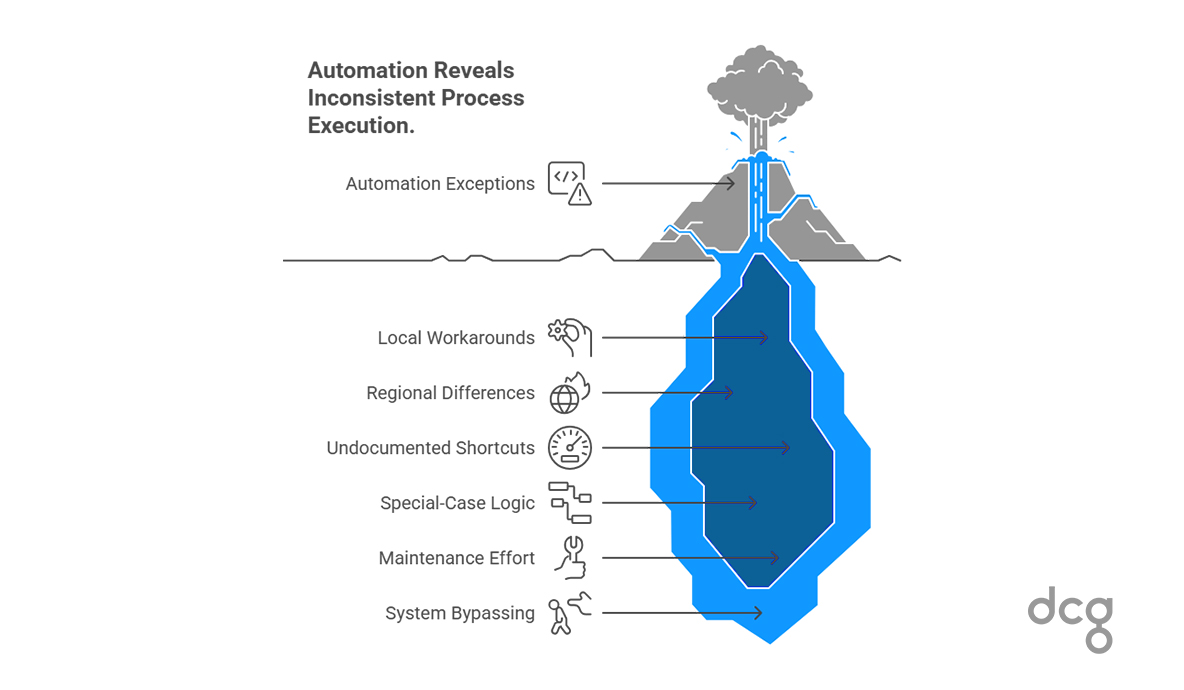
Inconsistent Process Variants
Documented processes rarely reflect how work is actually done. Local workarounds, regional differences and undocumented shortcuts are common in mature ERP environments.
Automation encodes a single version of a process. Every deviation becomes an exception.
As variance increases, automation becomes brittle. Special-case logic proliferates. Maintenance effort grows. Teams begin bypassing the system to get work done.
This is not a user-adoption problem. It is a visibility problem. Automation has simply revealed how inconsistent execution already was.
Unstable Master Data
Automation depends on data being correct, consistent and governed. When data ownership is unclear or stewardship is weak, automation does not correct the issue - it propagates it.
Incorrect joins, mappings, or hierarchies that were once isolated become systemic. Reconciliation becomes routine. Reports diverge from reality even though pipelines remain green.
These failures are often attributed to integration defects. In reality, they originate in process gaps around data governance.
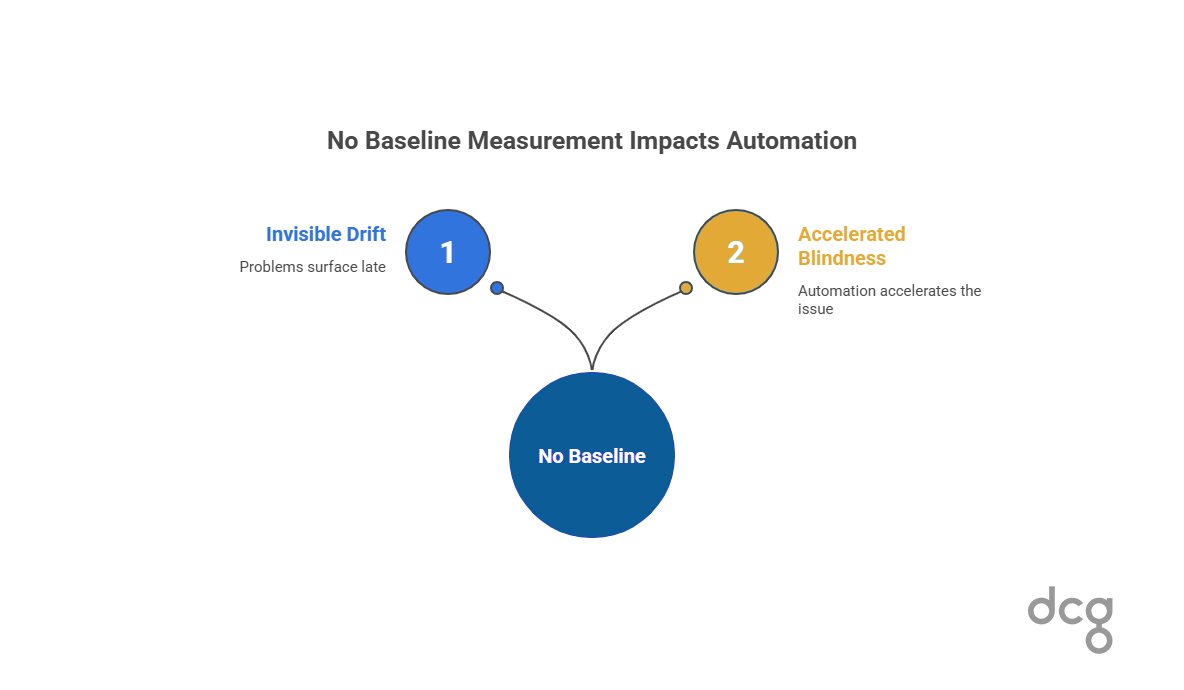
No Baseline Performance Measurement
Many teams cannot answer basic questions about their processes: how often they succeed, how long they take, or how many exceptions occur.
Without a baseline, automation removes informal detection mechanisms. Drift becomes invisible until it crosses a business threshold. Problems surface late, often through escalation rather than measurement.
Automation does not cause this blindness. It accelerates it.
Requirements Defined at the Solution Level
When requirements focus on what an automation will do rather than what the process must guarantee, assumptions are embedded into code and scaled.
Control points, rollback behavior and correctness criteria remain implicit. Automation optimizes steps while weakening end-to-end integrity.
The result is a system that works most of the time and fails expensively at the edges.
Automation Applied to Volatile Processes
Processes with high change rates have short automation half-lives. When changing discipline is weak, automation becomes a maintenance burden rather than a stabilizer.
Small upstream changes ripple across dependent workflows. Break-fix work replaces planned improvement. Scaling stalls not because automation failed, but because the process was never stable enough to scale.
Automation Applied to Low-Value, High-Exception Work
Not all work is a good candidate for automation. When exception handling and coordination dominate, automation adds monitoring and engineering dependency without reducing risk.
Costs rise. Confidence falls. Teams become fatigued by “small automations” that never quite work as expected.
These conditions do not originate in technology. Automation simply exposes them at scale.
The Maturity Mismatch
Most automation failures are sequencing failures. Organizations automate before they can reliably observe and measure how work actually executes. They scale before they stabilize.
A simple maturity progression illustrates the issue:
Observe → Measure → Stabilize → Optimize → Automate
Observation establishes visibility. Measurement creates a baseline. Stabilization reduces variance. Optimization simplifies. Automation then scales what is understood and controlled.
Automating before baseline understanding guarantees faster failure because it amplifies unknowns. The system becomes efficient at producing unreliable outcomes.
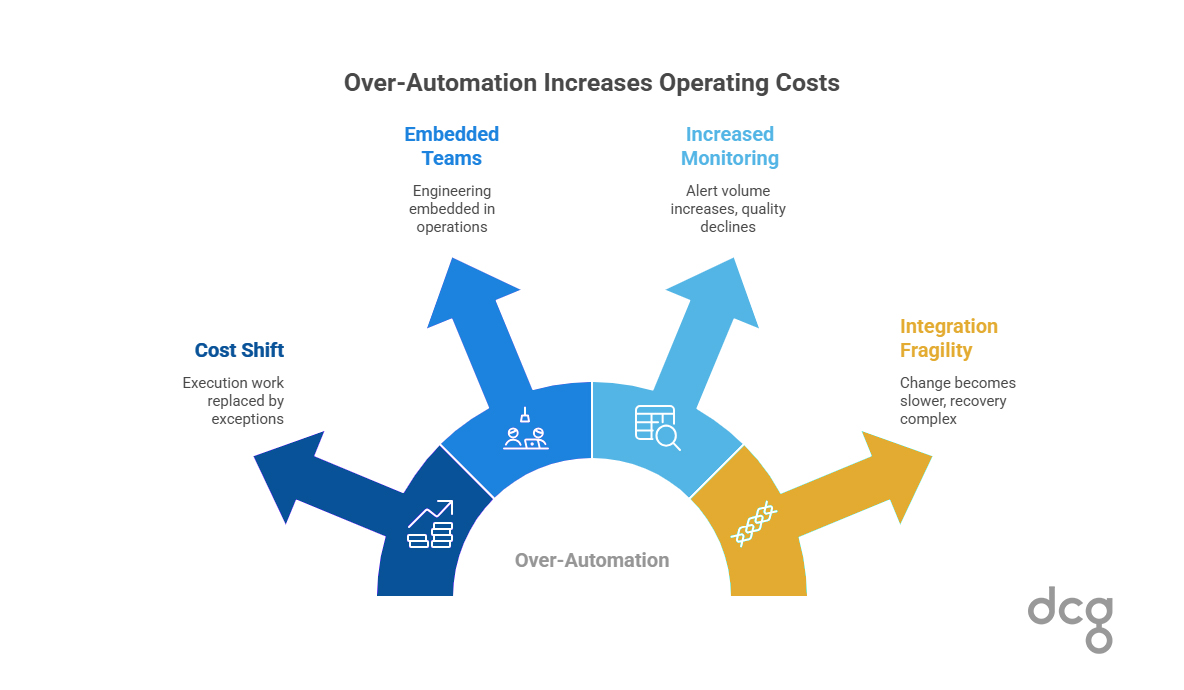
Why Over-Automation Increases Cost
Automation rarely reduces total operating costs in isolation. Instead, it shifts where the cost appears.
Execution work is replaced by exceptional throughput. Engineering teams become embedded in operations because process changes require technical changes. Monitoring overhead grows as alert volume increases and signal quality declines.
Integration fragility slows change. Recovery becomes more complex than manual work ever was. The system is still running. It just costs more to keep correct.
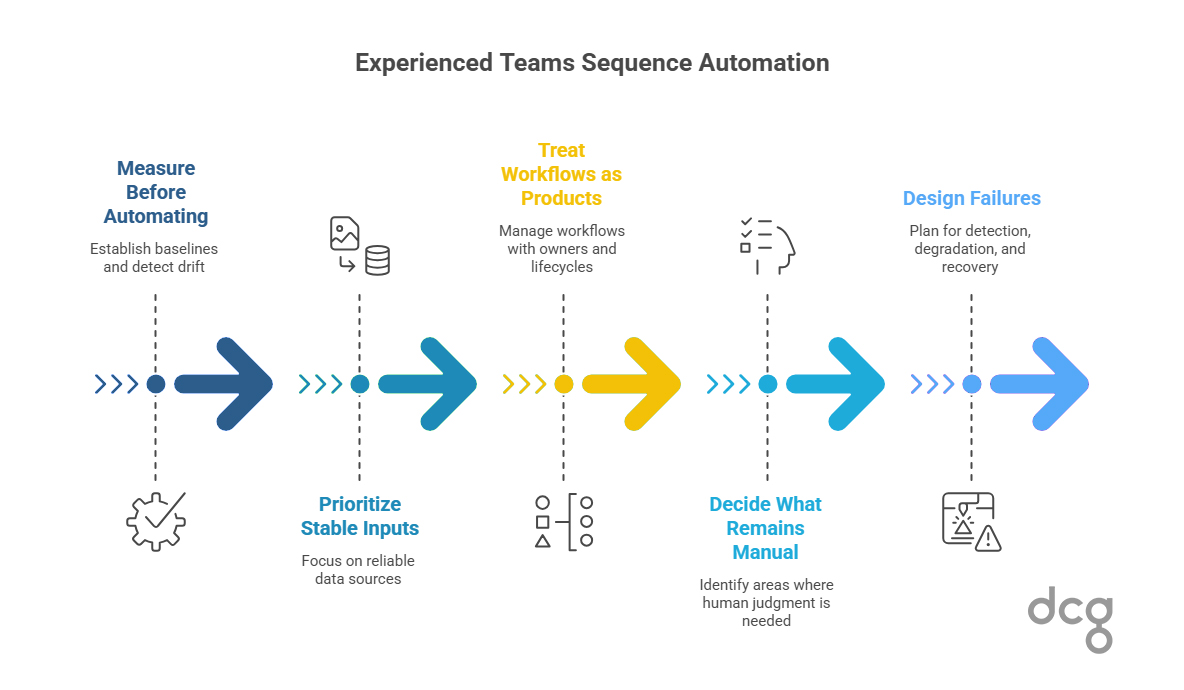
How Experienced Teams Sequence Automation
Teams that build durable automation behave differently. They measure before automating. Baselines exist. Drift is detectable. They automate selectively, prioritizing stable inputs, clear ownership and meaningful value density.
They treat workflows as products, with explicit owners, lifecycle management and operational accountability. They decide intentionally what remains manual, recognizing that human judgment can be safer and cheaper in volatile areas.
Most importantly, they design failures. Detection, degradation and recovery are planned, not assumed.
Better Questions to Ask Before Automating
The safest way to assess automation readiness is through questions:
- What happens when this fails?
- Who owns the exception backlog?
- What assumptions does this workflow rely on?
- How often does it succeed today?
- How will we detect drift?
- What degrades safely?
If these questions are difficult to answer, automation will amplify uncertainty.
Automation Risk Is a Process Maturity Problem
Automation is not the problem. Process maturity determines outcomes. Technology amplifies what already exists.
When automation is applied deliberately - after visibility, measurement and stabilization, it becomes a force multiplier. When applied prematurely, it scales risk quietly and expensively.
For organizations experiencing brittle automation despite “working” systems, the next step is not more tooling. It is understanding which process conditions are being amplified.
Primary next step:
The ERP Health Assessment provides a structured diagnostic to surface instability, exception ownership gaps, data weaknesses and measurement blind spots before automation scales them further.
Secondary follow-on:
For teams already dealing with stalled or high-exception initiatives, the Stalled Project Forensics Checklist can be used as a deeper, targeted analysis to isolate specific failure patterns and escalation drivers.
That understanding- not more automation-is what ultimately makes ERP environments safe to scale.

.png)

