

What a Single Hour of Outage Costs by Industry
For most enterprises, downtime is discussed as an IT problem. Tickets are opened, severity levels are assigned, and escalations are requested. But for your business, downtime isn’t just an IT problem; it’s a measurable financial event.
Most leadership teams track cloud spend down to the dollar. Very rarely do they track the hourly cost of an outage, even though downtime can erase more value in 60 minutes than a full year of “support savings” ever recovers.
Across industries, benchmarks consistently show that one hour of downtime can cost anywhere from tens of thousands to several million dollars, depending on transaction volume, regulatory exposure, and system interdependence.
As Microsoft environments become more integrated across Azure, Microsoft 365, Dynamics, and hybrid infrastructure, outage risk no longer scales linearly; it compounds. The difference between resolving an incident in 30 minutes versus two hours is no longer marginal. It is measurable, and in many industries, it is material.
The hard part is making it operationally actionable:
- What’s the cost exposure per hour in your industry?
- How does that cost scale as MTTR stretches from 30 minutes to 2+ hours?
- Why do some support models routinely extend outages even at premium price points?
- What’s the value of reducing MTTR by 10–30% in real dollars?
A Benchmark Reality Check: “One Hour” Is Rarely Just One Hour
Downtime cost is not a single metric. It is the sum of multiple forces:
- Direct revenue loss (missed transactions, abandoned carts, service credits)
- Productivity loss (idle labor + rework)
- Operational disruption (fulfillment, clinical operations, contact centers, production)
- Risk & compliance (penalties, reporting events, audit findings)
- Recovery costs (overtime, consultants, incident response, tooling)
- Reputational damage (hardest to quantify, often largest long-tail)
What changes by industry is how quickly these costs accumulate. Across benchmark studies and enterprise analyses, representative hourly outage costs often fall into broad ranges:
- Financial services: Hundreds of thousands to several million dollars per hour
- Healthcare and life sciences: Significant revenue and regulatory exposure within minutes
- Manufacturing and logistics: Production stoppages and supply chain ripple effects
- Technology and telecommunications: Customer-facing disruption and SLA penalties
- Public sector, education, and nonprofit: Service delivery failure and public accountability
Industry surveys commonly report hourly downtime costs of $300K+ for mid-size and large enterprises, with a significant share reporting $1M-$5M+ per hour. New Relic’s 2025 observability research also highlights that many high-impact outages cost an average of ~$2M per hour, underscoring how quickly financial exposure compounds once an incident reaches “material business impact.”
.png)
Ranges shown reflect benchmark studies and industry surveys. Actual exposure varies by scale, transaction density, and regulatory environment.
This is why the “one hour of downtime” concept is often misleading. In practice, the actual cost reflects not just the outage itself, but the effort required to recover, validate, and stabilize the environment afterward.
The most effective way to limit this cascading impact is to reduce the time it takes for the right engineer to engage.
Why These Numbers Matter: Downtime Scales Nonlinearly
An outage rarely stays contained. Modern Microsoft environments tie together:
Azure identity, network, compute, storage, M365 collaboration, endpoint management, security controls, and business apps. As integration increases, “one incident” becomes multiple downstream failures, and the recovery effort expands.
This is why downtime costs behave more like a curve than a flat line—once critical services or security controls are affected, the business impact escalates quickly.
Time-to-Engineer Engagement: The Silent MTTR Multiplier
Mean Time to Resolution (MTTR) is frequently cited but rarely dissected. What actually drives MTTR higher is not complexity alone; it is delay.
Specifically:
- Delay before a qualified engineer owns the issue
- Delay caused by routing, reclassification, or handoffs
- Delay from lack of environmental familiarity
In triage-heavy support models, incidents often move through structured intake and prioritization stages before meaningful engineering work begins. These processes are designed for scale and consistency, but they introduce friction when speed matters most.
Every minute an incident waits for the right expertise is a minute of accumulating business impact.
Even when the “right” engineer eventually arrives, the environment context has already degraded: logs roll, states change, workarounds accumulate, stakeholders escalate, and teams lose time aligning on the story.
This is the hidden link between support model design and outage cost:
- Delayed engineering engagement increases MTTR.
- Increased MTTR inflates downtime exposure.
- Inflated downtime exposure makes “premium support” hard to justify without measurable performance.
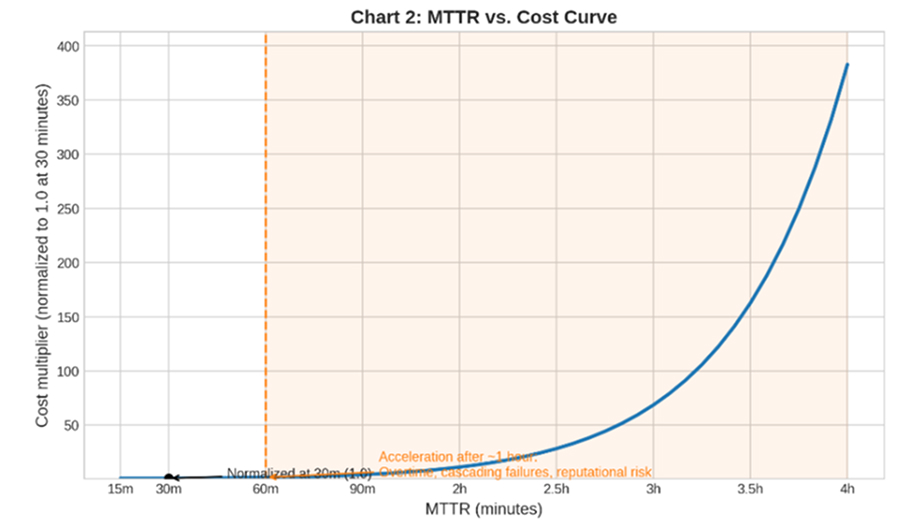
Every additional 30 minutes is not ‘just 30 minutes.’ It often triggers additional stakeholders, additional recovery tasks, and additional business impact.
Procurement’s Risk Equation: Paying More Without Reducing Exposure
Many enterprises assume that paying more for support reduces risk. In practice, this assumption does not always hold. Support pricing tied to overall Microsoft spend increases predictably as cloud usage grows, regardless of whether:
- Incident volume increases
- Resolution speed improves
- Root causes are addressed
Support renewals are frequently treated like insurance. But insurance has two requirements:
- You know what you’re paying for, and
- You can demonstrate reduced exposure.
When support pricing rises with cloud spend while incident experience remains inconsistent, Procurement gets stuck:
- costs grow,
- evidence stays thin,
- ROI becomes narrative rather than math.
This is where the outage-cost model becomes procurement’s most useful tool: it translates performance into dollars.
Benchmarks show many enterprises report downtime costs in the hundreds of thousands per hour, and a meaningful share in the $1M+ per hour band.
How Partner-Led Support Changes the Outcome
Partner-led, usage-based support models are designed around engineering accuracy, not entitlement breadth. They focus on:
- Immediate access to senior engineers
- Clear ownership from engagement to resolution
- Environment familiarity over time
- Strategic, targeted escalation when necessary
- Transparent reporting tied to actual work performed
This design directly addresses the drivers of prolonged outages. By shortening time-to-engineer engagement and reducing handoffs, MTTR compresses and with it, financial exposure.
DCG’s model aligns naturally with outage economics:
- It prioritizes time-to-engineer engagement,
- measures performance through SLA discipline and reporting,
- and ties cost to real engineering effort rather than cloud-spend inflation.
Licensing changes, EA eligibility shifts, and CSP adoption are decoupling support from licensing. Enterprises now have the freedom to evaluate support on performance, not default alignment.
Next Steps: Turn Outage Risk Into a Support Decision You Can Defend
If outages are financial events, then support is a financial control!
Read Support Cost Breakdown: The Real Math Behind Your Microsoft Invoice
%202.png)
.png)

